ResNet for Dummies : 101
May 07, 2026
Imagine you are training a 20-layer neural network and get 85% accuracy. You think: more layers equals a better model. So you train a 56-layer network on the exact same data.
It gets worse accuracy. On the training data itself. lol,

This isn't overfitting. The model isn't memorizing too much, it just couldn't learn. And nobody had a clean explanation for it. That's the problem ResNet solved. The fix was one line of code.
Why Training Breaks: The Vanishing Gradient Problem
When a neural network gets a wrong answer, you calculate a number called loss (how wrong was it?), then work backwards through every layer to figure out which weights caused the mistake.
The gradient for a weight tells you: if I nudge this weight slightly, does the loss go up or down? If the gradient is positive, decrease the weight. If negative, increase it. This is gradient descent and it's basically all that "learning" is.
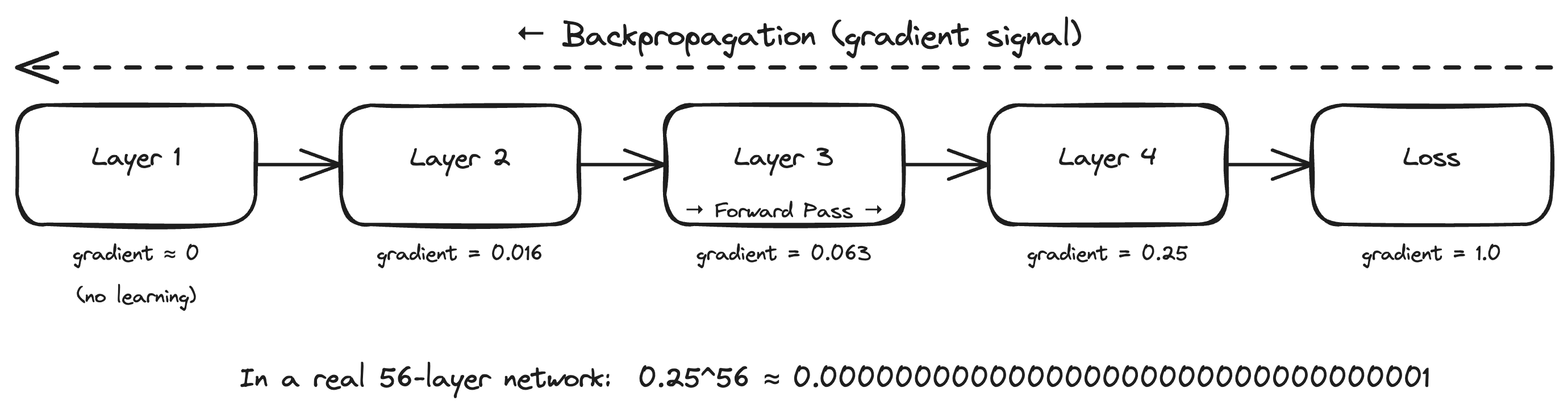
Here's where it breaks. Computing the gradient for a weight in layer 1 requires applying the chain rule backwards through every layer between layer 1 and the output. The gradient at layer 1 equals the gradient at layer 2 multiplied by layer 3, multiplied by layer 4... all the way to the end. You're multiplying a long chain of numbers together and such small numbers multiplied by other very small numbers [ between 0 - 1 ] will only give a smaller number .
Most networks at the time used sigmoid as their activation function. Sigmoid squashes any number to a value between 0 and 1. Useful for predictions, but here's the issue: during backprop you need the derivative of sigmoid, which is sigmoid_output × (1 - sigmoid_output).
sigmoid outputs 0.5 (the middle) → derivative: 0.5 × 0.5 = 0.25
sigmoid outputs 0.1 → derivative: 0.1 × 0.9 = 0.09
sigmoid outputs 0.9 → derivative: 0.9 × 0.1 = 0.09
The maximum is 0.25, but it's usually smaller. Multiply that through 56 layers and you get roughly 0.25^, which is essentially zero. The signal dies completely.
By the time the gradient travels from the output back to layer 1, there's nothing left. Early layers receive a gradient near zero, so their weights don't move & so those layers don't learn anything. They initialize randomly and stay random. The later layers do all the work but they're building on top of garbage features from untrained early layers.
This is the vanishing gradient problem. The 56-layer network had 56 layers on paper but only the last 10-15 were actually learning anything. The rest were dead weight, which is exactly why it performed worse than the 20-layer version.
Other Attempts to Solve This
Before ResNet, researchers tried switching from sigmoid to ReLU (Rectified Linear Unit). ReLU's derivative is 1 instead of 0.25, so gradients don't shrink as much when moving backwards. ReLU helped, but it wasn't enough. Training very deep networks was still difficult.
The Fix: Skip Connections
Kaiming He and the team at Microsoft Research figured this out in 2015. Instead of asking each layer to learn a full transformation from scratch, what if the input got a shortcut to bypass the layers and add itself back at the end?
So instead of a block computing output = F(x), you compute:
output = F(x) + x
You take the original input x, run it through the layers to get F(x), then add the original input back before passing it forward. These are called skip connections or residual connections. The network only has to learn the residual, meaning what needs to change, not the full output from scratch.
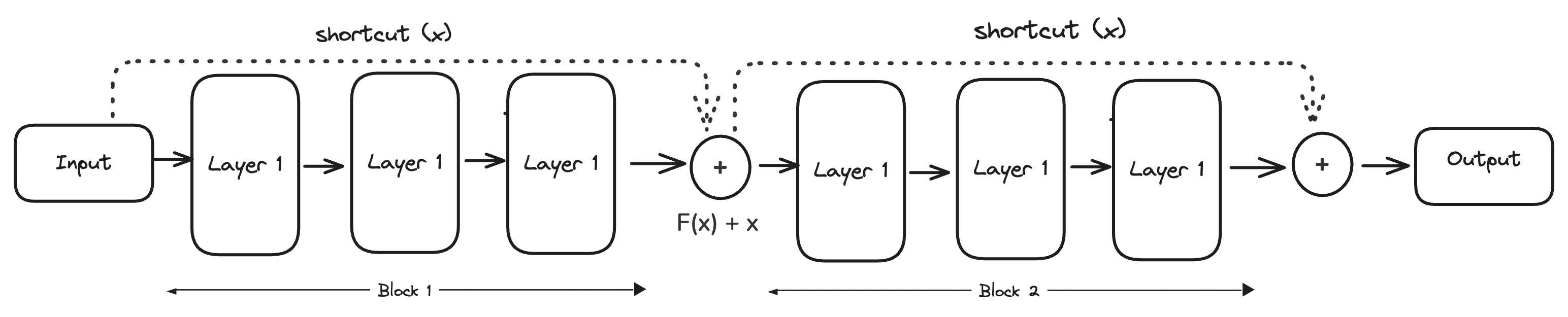
Here's why this fixes both problems at once.
Data comes in and splits into two paths. One path goes through the block (transforming it). The other goes around it (unchanged). Then they combine back together.
If the block has nothing useful to add, it outputs zero. Zero plus the original input equals the original input. The block doesn't need to learn how to pass data through perfectly, it just learns to output nothing.
Learning signals work the same way on the backward pass. Gradients travel through two paths. If one path dies out, the other keeps the signal alive. Early layers actually get feedback now and they're no longer starved of information.
What a Residual Block Looks Like
class ResidualBlock:
def __init__(self, transformation_function):
self.F = transformation_function
def forward(self, x):
residual = x
out = self.F(x)
out = out + residual # the skip connection
return outThe entire ResNet idea lives in one line: out = out + residual. It takes the original input and adds it directly to the output of the transformation, bypassing all layers in between. It costs basically nothing, just an elementwise addition.
What This Unlocked
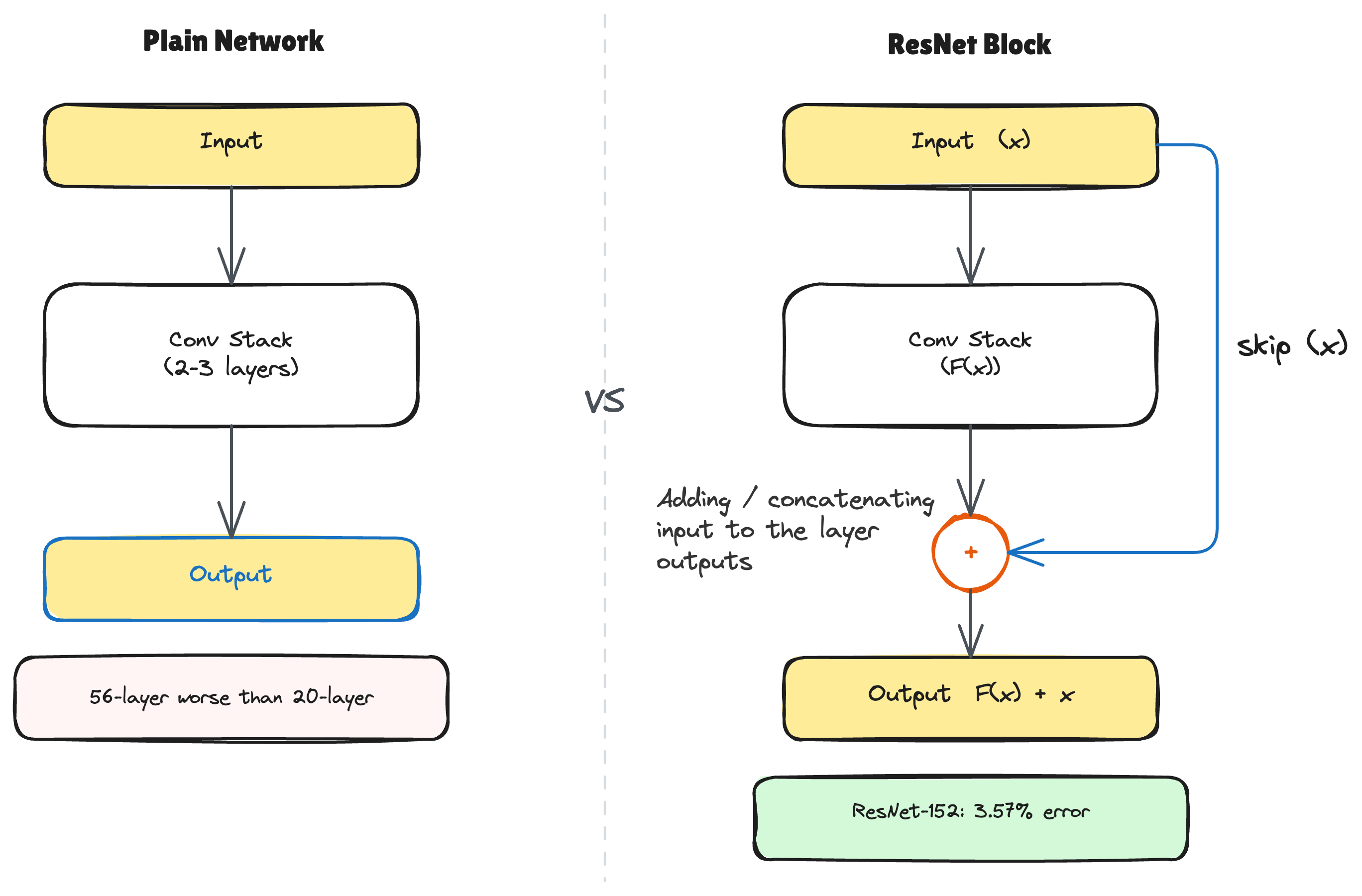
Before this paper, networks deeper than about 30 layers were practically unusable. Everyone had quietly accepted this as a hard ceiling. After ResNet, the team trained a 152-layer network and entered it in the 2015 ImageNet competition. They got 3.57% top-5 error rate. Human-level performance on that benchmark is around 5%. The machine was now better than us at recognizing images, running on a depth that nobody had successfully trained before.
ResNet-50 and ResNet-101 became the standard backbone for almost every computer vision system built after 2015. And the skip connection idea spread far beyond CNNs. Transformers, the architecture behind every major LLM today, use residual connections after every attention layer and every feedforward block. The model I used to refine my English for this blog was using the same output = F(x) + x trick.
Outro for Dummies
The model was failing not because it was too powerful, but because it had no easy way to say "I have nothing useful to add here, just pass it through." One + x fixed that, unlocked 150+ layer networks, won ImageNet, and quietly became the backbone of modern deep learning.
Thanks for making it to the end! If this clicked for you or if you want to argue about it, hit me up on Twitter / X or LinkedIn.